

#datascience #datathinking #aideate

10. Feb. 2020 |
- min Lesezeit
This is the first article of a two-chapter series, where we want to document our learnings on how to make our company management’s life easy in getting the best out of our business data. The starting point was a scenario which is not so uncommon: data related to employees, projects and other relevant factors were stored in different places, using different formats, and there wasn’t a unified interface to access all of them. With a lean approach, we sat together - a data oriented product manager, the data team and our management people - and we identified the main pain points with the status quo and defined a set of features that the new management system should have. The need for a unified database and an easy-access interface emerged and we started working on it in an iterative way. The pyramid below provides orientation between the different levels of the setup we started to build, from data (the base) to the decisions it can triggers (the top).
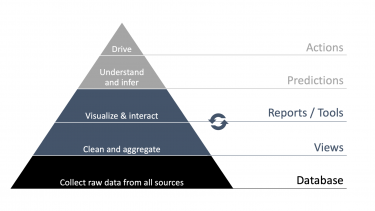
Typically, executives have to deal with several aspects of the business they lead, which can include managing employees and projects, measuring the performance at different levels (company, department, individual), keeping track of the sales funnel and so on. The different tasks are associated to different data, which are stored in different places and formats, and are consequently dealt with by means of a number of software solutions. This makes it difficult (and annoying) to stay in tune with all the available data, and more importantly it is painful to adapt to changes of different kind (business type, size etc.) That is why we decided to get our hands dirty and to unify all data sources in one place.
The first three questions to answer in order to start building our database were:
The answer to each question influences the next one, so we proceed in order.
In order to get an overview of all the available and possibly needed data we sat together - Product Manager, Data Team and Management - and filled the Data Landscape Canvas. This helped us to identify the relevant data sources to grasp from, in order to produce in the future the relevant reports. The sources we decided to start from are:
In addition, the exchange with our management team revealed the need for an interface to add, edit and delete entries from the database in a simple way, in particular for what concerns the status of employees. To this purpose we developed a web application (more on this in the next article of this series), which constitutes an additional data source to be integrated from the beginning. The need to integrate our sales dashboard, as well as other ideas on how to extend this pool by adding pieces of information that are relevant to the business, emerged during the exploration session. Nevertheless, we decided to start from the most essential setup, and having already a global overview of the possible future additional features helped us to design a flexible system, which could be easily extended in the future.
From the structure of our data it was clear that a relational database management system (RDBMS) was the best way to handle the relationships between the different entries: employees, clients, projects and tasks can be stored in different tables, and dependencies between them can be easily defined (e.g., there cannot be a task which is not associated to any project etc.). In order to choose the right system for us, we looked for something that satisfies the following requirements:
Among the various RDBMS available out there, our choice was PostgreSQL. Its broad community of active developers and users guarantees an extensive documentation and support, and its flexibility allows us - a diverse team including data engineers, analysts and scientists - to use our favorite setup (spoiler: it involves Python) and to be ready to extend and scale (more nerdy details here) in an easy way.
At this point we had to take some decisions in order to get the job done:
For the first point we decided to handle our database schema definition, connections and so on with the Python library SQLAlchemy. This is a great tool to interact with a relational database without writing any SQL. The mapping between the structured data coming from different sources and the tables of the relational database is handled by SQLAlchemy’s integrated Object Relational Mapper (ORM). If you are a fan of object-oriented programming (and we are!), you will agree that defining a table as in the snippet below is beautiful.
class Employee(Base):
__tablename__ = 'employees'
id = Column(Integer, primary_key=True)
name = Column(String)
Department = Column(String)
start_date = Column(Datetime)
def __init__(self, name, department, start_date):
self.name = name
self.department = department
self.start_date = start_date
The code is decontextualized, but this is not about writing a tutorial, rather showing the esthetical (and practical, if you are more a Python programmer than a data engineer) value of it. Just another example: let’s assume we want to list all the employees which belong to the “Data Ninja” department. In standard SQL we would write something like:
SELECT employees.id AS employees_id,
employees.name AS employees_name,
employees.department AS employees_department,
employees.start_date AS employees_start_date
FROM employees
WHERE employees.department = “Data Ninja”.
It is intuitive what each line does, but it is still a bulky piece of code for a simple task. SQLAlchemy does the magic for you: after initializing the connection to your database (via the URL pointing to the location where it is hosted), you can write a single line of code, as the Session class (part of the SQLA’s integrated ORM) translates it into SQL for you:
print(session.query(Employee).filter_by(department=”Data Ninja”))
Similar syntax allows one to create, edit and delete database records, just writing Python code. You will find tons of tutorials (on top of the already nice official documentation) to guide you through your first steps with SQLAlchemy, we encourage you to go for it!

For what concerns hosting our database, a cloud-based solution was the best option for us in terms of accessibility, scalability and feasibility. Due to its large set of features and tools that can be easily integrated with one another, we chose Google Cloud, answering the first and last points in one go. Cloud SQL offers the possibility to host the database and to easily connect it to the relevant sources via Cloud functions, with contained storage prices and pay-only-when-you-use-it billing system for the database instances. Thanks to SQLAlchemy we could directly enable our cloud functions to read from and write into the database when triggered by the different sources:
This simple architecture will allow us to integrate new data sources, always following the same structure: we can define cloud functions that map the data objects to the database tables using SQLAlchemy’s ORM.
To conclude, defining our long-term goals together with the stakeholders from the beginning helped us to favour flexible and scalable solutions from the beginning. Moreover, internal collaboration within the team helped us selecting a set of development tools everyone is comfortable with. Now that our database is ready to go live, we need to define the relevant aggregates of data from different tables to be visualised in the reports, in order for our Management to gain insight on relevant aspects of the business. This will be discussed in the next chapter of this series, stay tuned!
#datascience #datathinking #aideate

#datascience #internship #maths

#datascience #ai #data-driven-product

#data #dashboard #data-driven-product

#data #data thinking #data science

#digital log #podcast #vodcast

#data #data science #data thinking

#machine-learning #data #data science

#producttank #data-driven-product #datentreiber
